Learn to Create a Sitemap File Generator in Python
I’ve been wanting to get back into Python for a while now, but I couldn’t find any ideas for small projects to get back into the language.
I used to develop frequently in Python more than 15 years ago, but as time went by, I abandoned this language in my projects.
So to put an end to this regret, I decided to get back into it.
After thinking about an idea for a small project that could get me back into Python, but also interest you, I thought I would develop a Sitemap file Generator.
If you don’t know what a Sitemap is, I’ll use the definition given by Wikipedia:
“A Sitemap is a representation of the architecture of a website that lists the resources offered, usually in hierarchical form.
It is most often a web page that allows the user to quickly access all the pages offered for reading, and facilitates the work of indexing robots.
Google proposed a protocol called Sitemaps in 2005. This protocol establishes rules to represent the map of sites in text or XML for the exclusive use of search engines.
A Sitemap is very important for the natural referencing of websites.
The Sitemap allows webmasters to include additional information on each URL, such as: the frequency of updates, the time of the last update and the level of importance of the pages.”
To discover all the details about the Sitemaps format, I suggest you visit the official website of the format: https://www.sitemaps.org/protocol.html.
You will see that the format is quite simple:
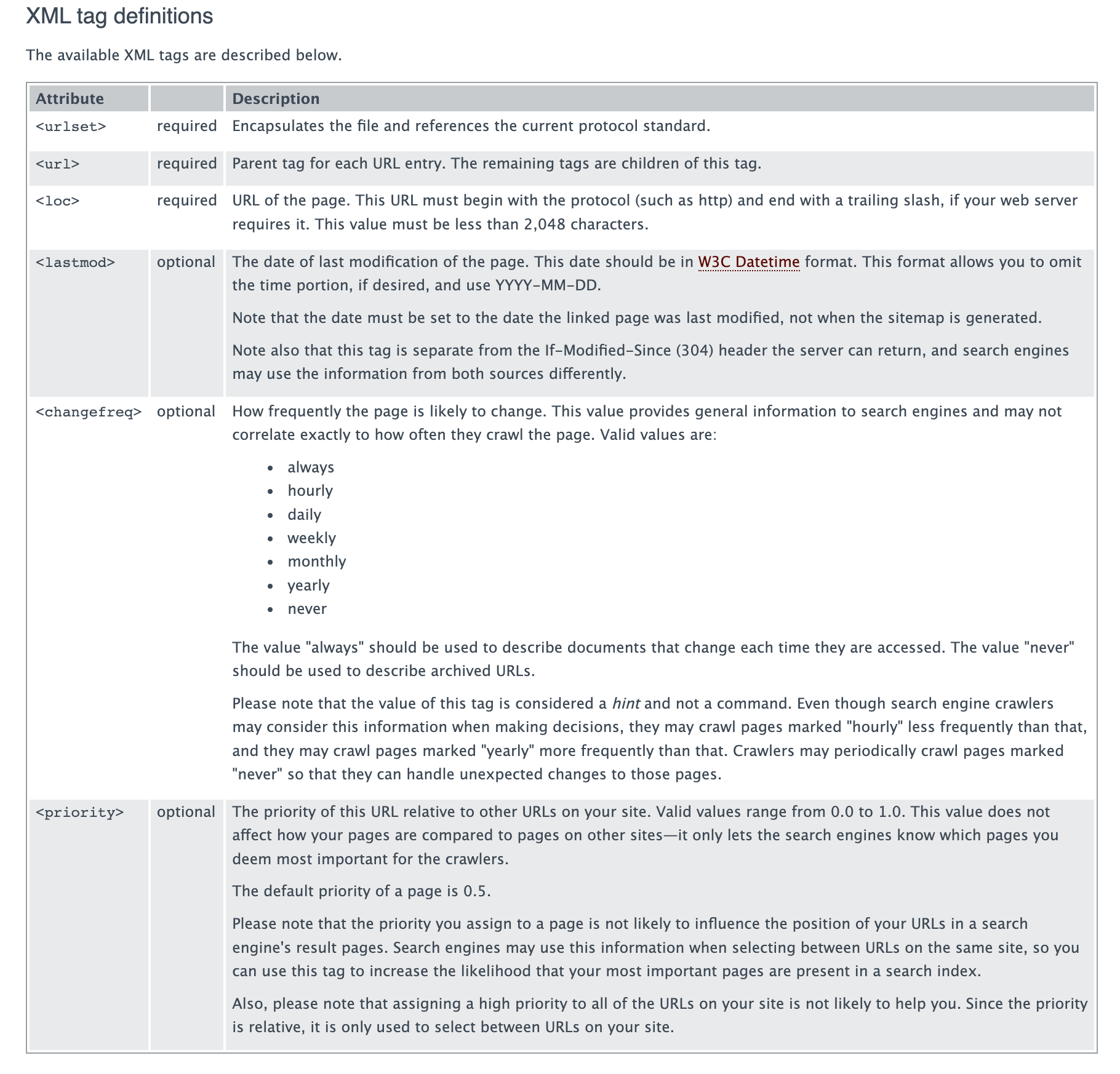
This simple format is perfect for a small project in Python.
Since the goal here is to have fun, I’ll just include the mandatory tags in the sitemap.xml file that my Python program will produce. You won’t see a last modification date right away for example, as that would require storing the crawled URLs in a database. But this could be something you could implement on your side to go further, or I could do it in a future article.
What should our Sitemap File Generator program do?
First of all, we need to define what our Sitemap generation program will do.
As you can imagine, the program will take as input the URL of a Web site whose Sitemap we want to generate.
The program will then have to retrieve the content of the source page and then parse this content looking for all the HTML links found in the document. Each link will then be explored by incrementing the depth level of the visited page about the root page.
When all the Web pages of the root site and its descendants have been crawled, it will be time to generate the sitemap.xml file.
The most interesting part here is to calculate the priority of each page from the depth level compared to the root.
Exploration of the Website for which we want to generate the Sitemap
Requests is a popular open-source HTTP library that simplifies working with HTTP requests. We will use it to call the web page.
The call is done as follows:
page = requests.get(url)
Nothing special.
Next, we will test the status of the result of the HTTP request. In case the return is OK (HTTP code = 200), then we can proceed to the parsing of the page obtained.
For parsing, I decided to use BeautifulSoup which I usually use in other languages. This will simplify the use within the program.
From the content of the page, the instantiation of the HTML parser is done as follows:
soup = BeautifulSoup(page.content, “html.parser”)
Then we have to recover all the HTML links of the page which are materialized by a tag a. We then iterate on it to recover the content of the href attribute which corresponds to the new page which will be explored then.
We take care to manage the case whether the page points to a page of the same domain or not. If it is not the same domain, we do nothing because our goal is to limit ourselves to the URLs of the root’s site, not to go see beyond the Web.
We can go and launch the exploration of the Web page found via a recursive call to our exploration method.
This gives us a crawl method within a SitemapGenerator class:
The small subtlety of this code is that we add the page at the first pass within a dictionary which is a member of the SitemapGenerator class and if the page is already present in the dictionary, we take care to check that the exploration level is not less than the previous one.
The goal is to have for each URL of the Website the closest level of exploration to the root.
Generating the XML Sitemap file
Once all the URLs of the root’s Website are stored within our class after the crawling, we must move on to the generation of the Sitemap.
This will be done within a generatefile method.
In this method, we will iterate on the items of the previously filled dictionary to store the URLs found by depth level within a map of lists. The final goal is to have a Sitemap file with page locations ranked with a priority between 1.0 and 0. Of course, we have no interest in telling search engines that a page has a priority of 0. We will have to take care to limit the lowest priority listed in the Sitemap file.
For the generation of the XML file, I use the ElementTree library which does the job, which is the main thing. There may be better, but for my needs, it will be sufficient.
I create the root object, then I will iterate on the elements of the list map.
For each level of depth, I will then iterate on the list of stored URLs and add to the XML root a new URL with the mandatory elements loc and priority.
At the end of the iteration loop, we just have to call the write method on the ElementTree object created from the root to create the sitemap.xml file.
This gives us the following code for the generatefile method of the SitemapGenerator class:
Using our SitemapGenerator class to generate the Sitemap of a Web site
We will now use our SitemapGenerator class to generate the Sitemap of a Web site.
We instantiate a SitemapGenerator object by passing in parameters the Web site whose Sitemap we want to generate and the name of the Sitemap file produced as output.
Then, it remains to call the crawl methods by launching with the root URL and the initial depth level which is set to 0 for the root. This will allow it to have a priority of 1 afterward.
Finally, we have to call the generatefile method.
This gives the following complete code for our program to generate a Sitemap file in Python:
Our Sitemap File Generator in Action
The best part is here since we are going to put our program into action. For that, I use the runner within Eclipse. After some time of waiting, I get the sitemap.xml file, of which there is a part of the content below:
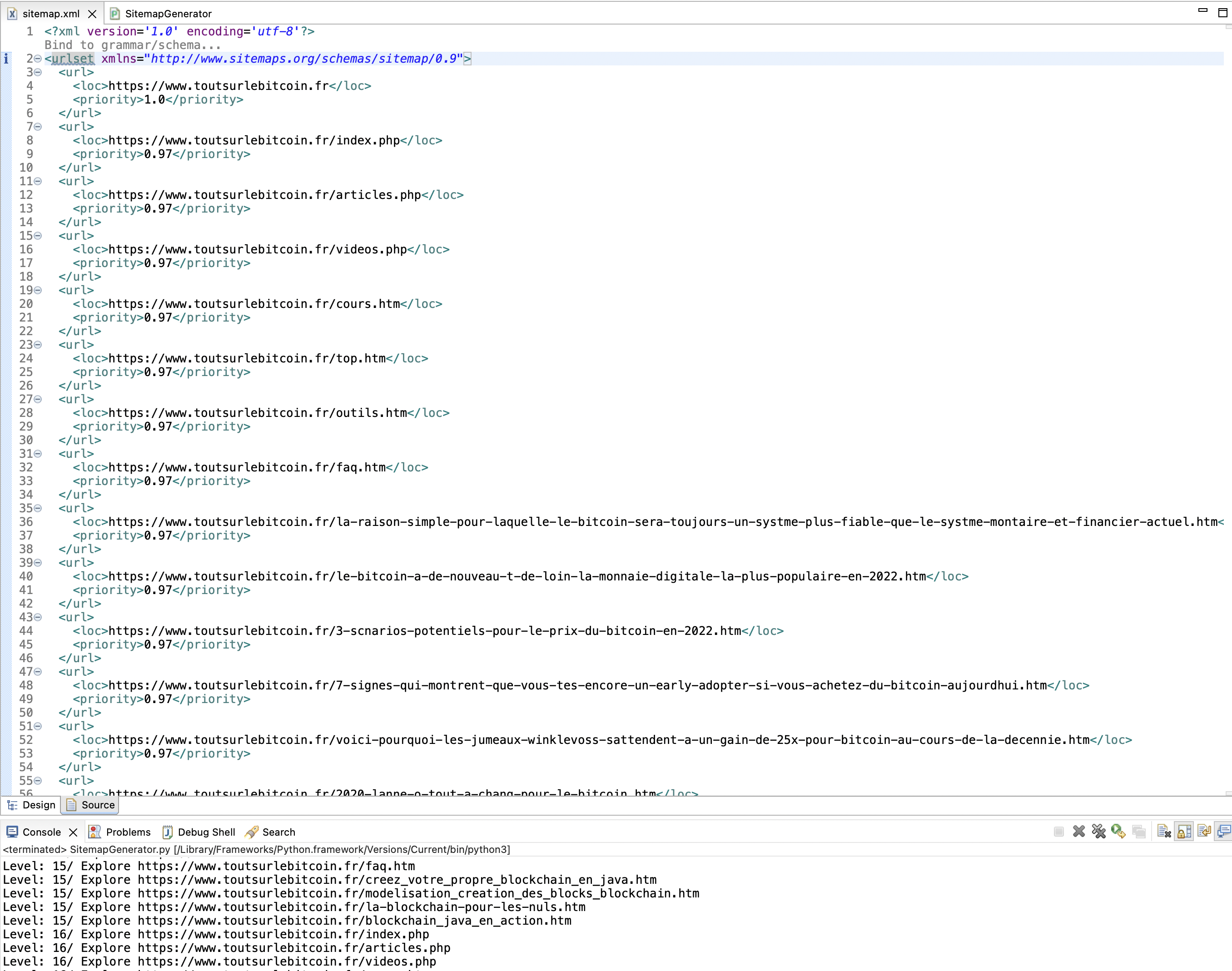
Our Sitemap is correctly generated.
Feel free to get the source code and test the program on your side and even make it evolve by adding new features.



Leave a Reply
You must be logged in to post a comment.