Building A Backlink Checker In Java
SEO is essential when you want to give your website visibility on the Internet. Indeed, most visits to websites are derived from search engines. I use the plural here but in reality, it would be more like a single search engine. You all know this search engine: it’s Google.
Google thus has more than 90% of the online search market share. His position is clearly hegemonic. This means that when you want to optimize the referencing of a website, you must, first of all, follow the rules set by Google. All practices aimed at improving your search engine positioning are part of what is called Search Engine Optimization (SEO).
At the heart of SEO is the essential criterion of backlinks. The more quality backlinks your website has, the better it will be positioned by search engines. Knowing your number of backlinks is therefore essential. In this article, I learn you how to build a Backlink Checker in Java.
What Is A Backlink?
Before going any further, I will start by defining the concept of Backlink precisely. If you are already used to the SEO domain, this will not be anything new for you. On the other hand, it will allow people less experienced in these SEO issues to start on a good basis.
A Backlink for a given web resource is a link from another website to that resource.
A web resource that can be a website, web page or web directory.
In this article, our goal will therefore be to build a program that will input a web resource and output the number of Backlinks to that web resource. In addition, the program we will develop will be able to list the original links of these Backlinks but also the HTML anchors used with these respective links.
Creating The Java Project
To develop this Backlink Checker, I chose the Java programming language but the principle is the same no matter what language you choose.
The first step is to create a Java project using Maven as a dependency management tool.
In order to easily parse the content of the web pages I will scrape for our program, I will use the Jsoup library. Finally, I would also need to manipulate multiple-value maps as part of the program. To do this, I will rely on the Apache Commons Collections library.
Here are the two dependencies to be added to the Maven POM (Project Object Model) of the project:
Creating The Web Crawler
Before you can count the number of Backlinks of a given web resource, you must have browsed the web from URLs to URLs. The program in charge of carrying out this work is called a Web Crawler.
Our first job is to create a Web Crawler.
To do this, I create a MyCrawler class within which I define the following properties:
- A String for the root domain from which the Web Crawler will start its work.
- A Boolean indicating whether the Web Crawler should only be limited to the path of URLs in the same domain as the root.
- An integer indicating the maximum depth to which the search should go.
- A multi-valued map that will store all discovered links in memory. Thus, if site A makes an HTML link to site B with an anchor “Site A”, the map will store these 3 informations.
In order to store the outgoing link from site A to site B with the anchor “Site A”, I create an Out object:
I then have to create a crawl method that takes as input a URL and the current depth level associated with the URL being processed.
To start, I display the URL during the visit and then I retrieve the domain associated with this URL. This is necessary if you want to limit the work of the Web Crawler to the domain associated to the root of the exploring.
If the domain can be visited and the maximum exploring depth has not been reached, the URL passed as a parameter will then be processed. To do this, I connect to the URL using the static connect method of the Jsoup object by passing the URL as an input. Then, I call the get method to get the Document instance representing the content of this URL.
The Document object got offers a select method that allows you to pass selection requests on the content of the HTML page it represents. In this specific case, the following request is therefore entered: “a[href]”.
Then we increment the search depth and iterate on all the Element objects obtained thanks to this query.
For each link, I retrieve the anchor by calling the text method of the Element object instance and the content of the href attribute. I store the association between the URL being processed and this destination URL associated with the anchor pointing to it.
Finally, all that remains is to recursively call the crawl method for visiting this destination URL, which in turn will become the processing URL.
All this gives us the following code for the Web Crawler:
Web Crawler In Action
In order to test our implementation of a Web Crawler, we ran the MyCrawler class by limiting the exploring to the domain of the root website. From the start, we can view the links found during the visit of our Web Crawler:
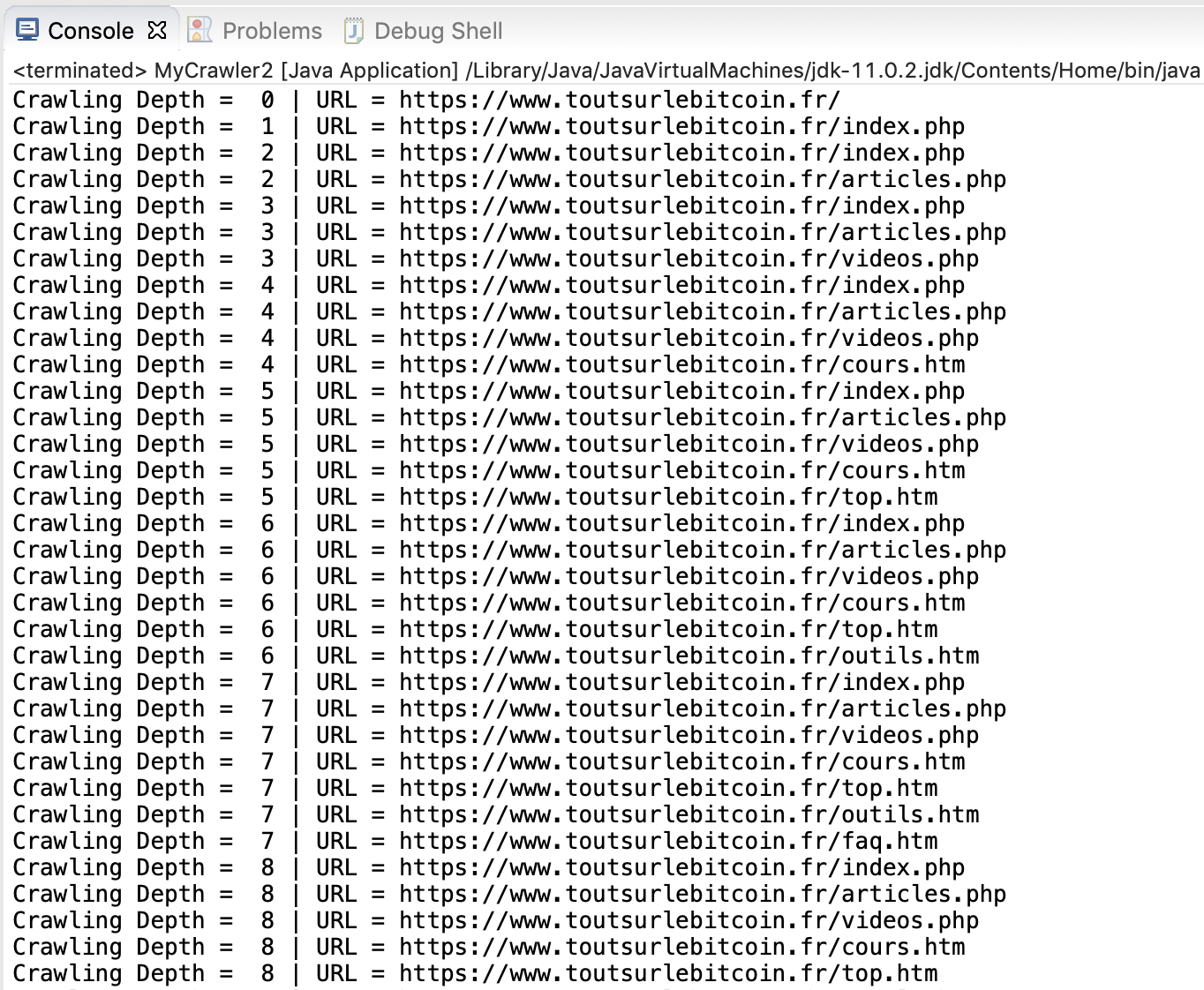
As the Web Crawler continues its exploring work, the links of the root website appear:

At the end of the execution of the Web Crawler, we have at our disposal a complete mapping of all the links inside the root website on a depth of 10 levels.
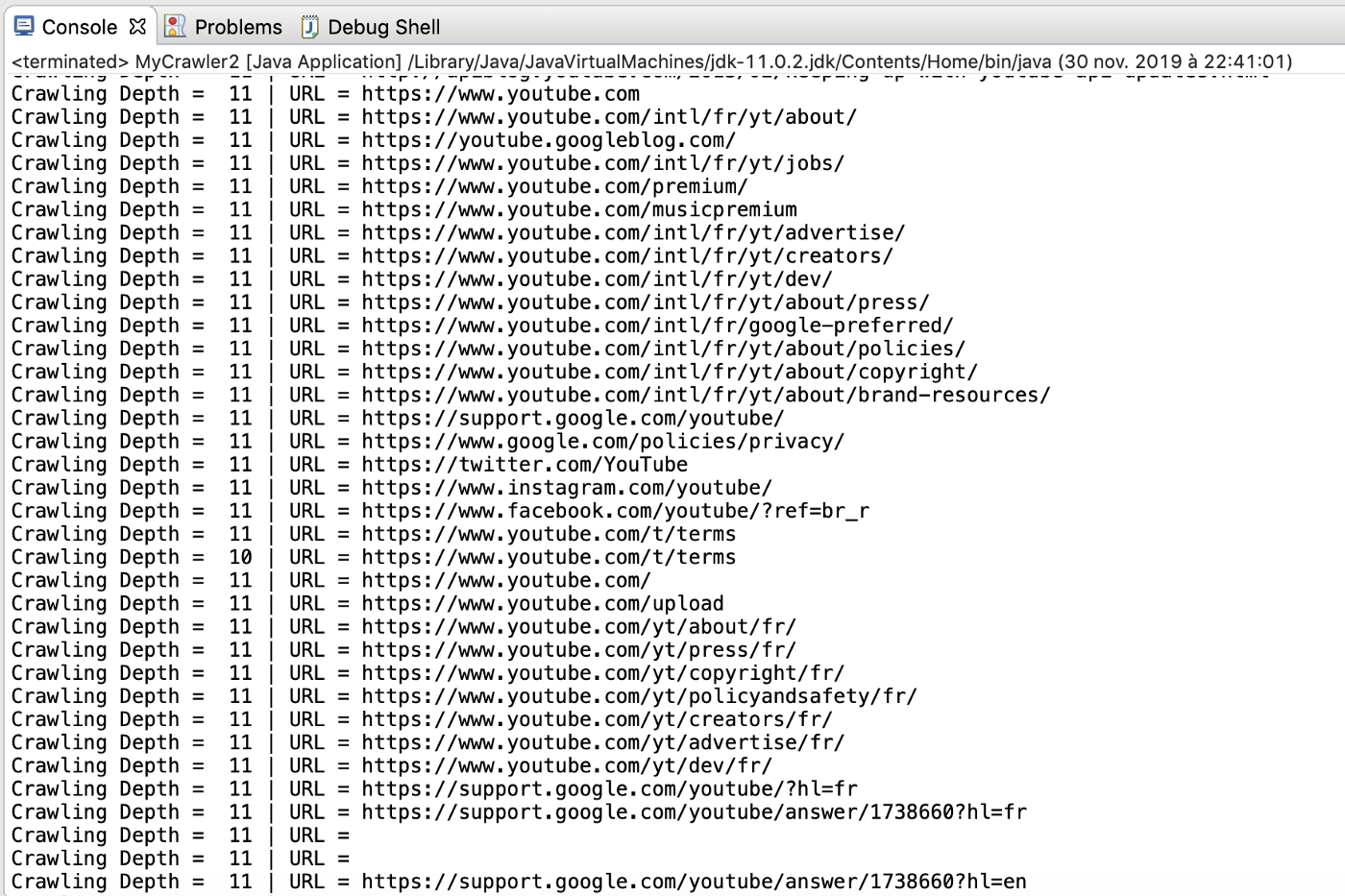
Of course, the work of search engines goes much further since it consists in exploring all the domains present on the Web to build this link mapping without any depth limitation.
With our MyCrawler class, we could launch a generalized search by setting the Boolean SAME_DOMAIN to false. The execution of the Web Crawler would then look like this:
Creating The Backlink Checker
From the mapping of the links obtained as a result of the Web Crawler work, we are able to find all the existing Backlinks as well as the HTML anchors used to point to the web resource passed as input.
Our Web Crawler is limited to one domain or a certain depth. The operation remains more or less the same for Google’s Web Crawler except that it explores all domains of the Web.
In fact, Google is able to know all the Backlinks available on the Web for a given resource. In our case, Backlinks will be limited to the mapping obtained by our Web Crawler.
To calculate the Backlinks of a given resource on the root website, I create a printBacklinks method that takes this resource as input. I declare a list of Tuple objects that will be used to store the calculated Backlinks.
This Tuple object has two properties:
- A href string representing the parent link of the web resource.
- A list of String named anchors representing the anchors used by this parent link to point to the web resource.
All this gives us the following code:
The next step is to iterate on the multi-valued map that represents the mapping of the links discovered by the Web Crawler.
For each starting link, the associated Out object is retrieved. If this object has its href property which is equal to the URL passed as a parameter whose Backlinks we want to calculate, we will continue the work.
This work consists in creating or updating a Tuple object associating the starting link and the associated anchor to point to the URL. This work being carried out by taking care not to add several times a Tuple corresponding to the same parent link.
When a parent link is already present in the list of Tuple objects representing the Backlinks, the anchor list is updated.
Once this work is completed, the number of Backlinks found for the web resource in question can be displayed on the screen, as well as details of all Backlinks and the anchors used by each Backlink to point to the web resource.
This gives us the following complete code for the MyCrawler class:
Backlink Checker In Action
It is now time to activate our Backlink Checker to calculate all Backlinks for a given web resource. Here, I chose to have the Web Crawler work on a specific website, namely: “https://www.toutsurlebitcoin.fr”.
In fact, I will choose a web resource from this site whose Backlinks I want to know, then launch the program which gives us the following output:
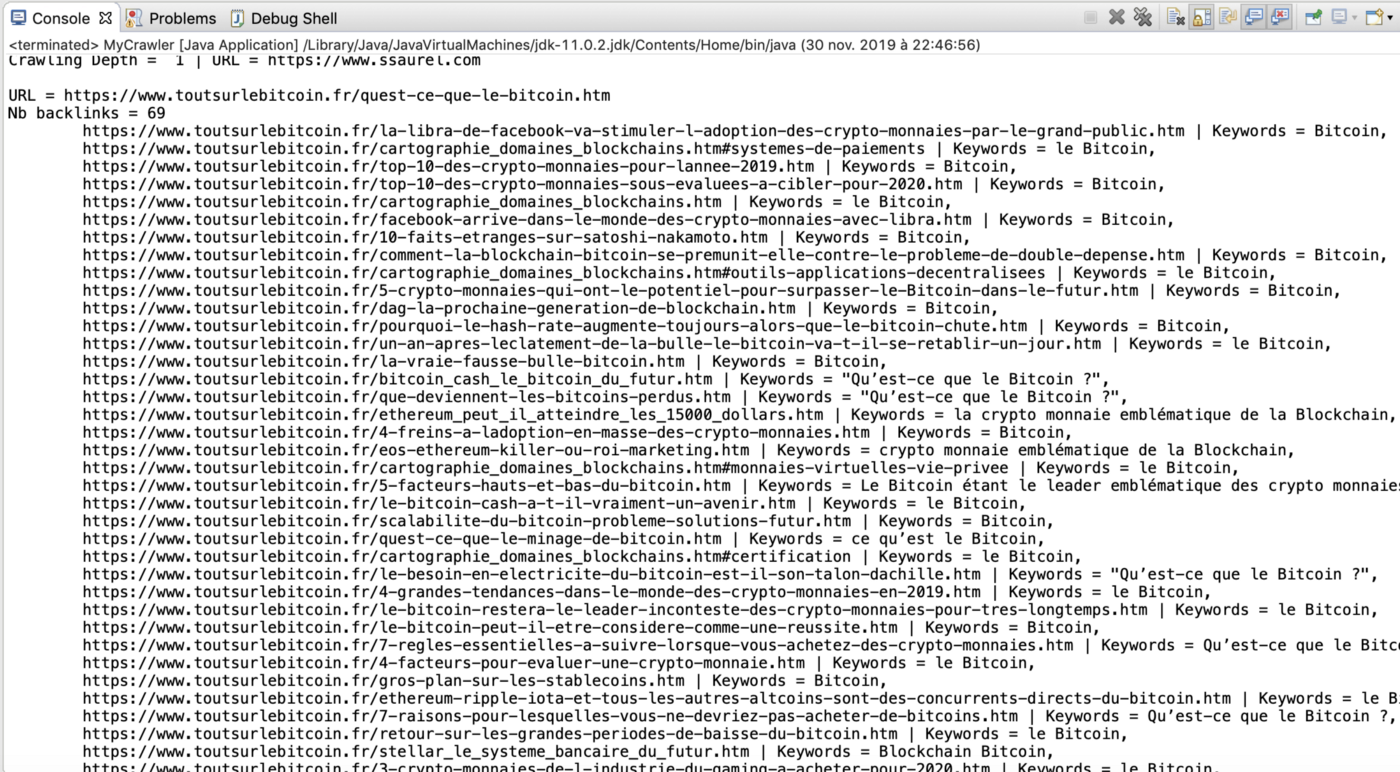
Following the execution of our Backlink Checker, we learn that the web resource targeted has 69 Backlinks within the website that had served as the root of the Web Crawler.
Details of each of these Backlinks are also displayed.
To Go Further
Our Backlink Checker is fully functional. As you may have understood, the essential point to having a quality Backlink Checker is to have as complete a web mapping as possible. This web mapping is done by a program called Web Crawler.
A first significant improvement to our program would be to parallelize the work of the Web Crawler.
Then, it would be useful to store the websites explored and their links in a database to save time by restarting the Web Crawler at a given moment of the previous exploring rather than starting from scratch each time.
At the level of search engines like Google, you must also keep in mind that to have the most complete and up-to-date mapping possible, they must constantly maintain a list of root domains from which to launch their Web Crawler. In addition, these web exploring programs must also run continuously to ensure that web mapping is as up-to-date as possible.
Starting from the implementation of the Backlink Checker built in this article, you have the ideal starting point to go further in this fascinating domain.



Leave a Reply
You must be logged in to post a comment.